What is RAG-DocBot?
RAG-DocBot is a self-hosted, on-premise AI platform designed for companies that want to run an internal, privacy-preserving AI assistant on their own infrastructure — with no data ever leaving their network.
It is a backend service and tooling — a separate UI project provides the frontend. Together they form a complete document-grounded AI assistant that runs entirely on your own servers.
Vision
RAG-DocBot is built around the principle that your data should never leave your infrastructure:
- Full data ownership — no SaaS dependency, no third-party data processing
- On-prem deployment — including air-gapped environments with no outbound internet
- Configurable for CPU and GPU — runs on commodity hardware as well as GPU-accelerated servers
- Transparent pipeline — every step from document ingestion to answer generation is visible and controllable
- Scales from small teams to enterprise — license-gated tiers to match your workload
Key Capabilities
| Capability | Description |
|---|---|
| On-premise by design | By default all data stays on your infrastructure (no telemetry, no external API calls). Optional OpenAI backend mode can be enabled explicitly for hosted chat inference. |
| Source connectors | Ingest documents via file upload, GitHub, Slack, Google Drive, or local directories. |
| Metadata extraction rulesets | Define per-source regex rules (connector or integration) to extract structured fields (patient IDs, article numbers, dates, document types) from your documents. Enables filtered, sorted, and grouped retrieval. |
| Analytics dashboard | Chunk distribution, metadata coverage, rule effectiveness, and priority audit metrics — per connector or integration. Requires Pro plan. |
| Streaming chat (SSE) | POST /api/chat supports Server-Sent Events streaming via Accept: text/event-stream for real-time answer delivery. |
| Scheduled syncs | Cron-based scheduler for automatic connector and integration syncs. Requires Pro plan or higher. |
| Audit logging | Append-only Postgres audit log covering chat, sync, and config lifecycle events, with admin query APIs and retention policies. Enterprise only. |
| Operational backups | Runbook and automation for backup and restore of Postgres, Qdrant, branding assets, and local models. |
| Intelligent search & retrieval | Five retrieval modes — semantic, hybrid metadata filtering, metadata-only, comparison grouping, and BM25 keyword fusion — with automatic intent detection that picks the right strategy for each query. |
| Async job system | Document ingestion and indexing run as background jobs — no blocking the API. |
| Persistent storage | PostgreSQL for application data, Redis for live job state, Qdrant for the vector index. |
| JWT auth & RBAC | Role-based access control with viewer, editor, and admin roles. |
| TOTP MFA (all tiers) | Time-based one-time password second factor for any authenticated user account on Free, Pro, and Enterprise tiers. Enrollment returns a QR code and 10 single-use recovery codes. See MFA / TOTP. |
| OCR for scanned documents | Optional OCR for scanned PDFs and image files (INDEXING_OCR_ENABLED), with additive extraction so text-native documents keep the fast path. See OCR & Table Extraction. |
| Additive table-row extraction | Optional extraction/indexing of table rows from PDF, DOCX, Excel, and CSV (INDEXING_TABLES_ENABLED) alongside normal text chunks. See OCR & Table Extraction. |
| External LLM backend (OpenAI) | Optional hosted-chat mode via LLM_BACKEND=openai with OPENAI_* settings. Local embeddings remain in-cluster. See Using OpenAI as the LLM backend. |
| Email-based password reset | Local users can request reset links by email via /api/auth/forgot-password and /api/auth/reset-password, with dedicated rate limiting and SMTP/console providers. See Email-based password reset. |
| Connector-aware document operations | Upload/delete/move document operations can target specific connectors rather than only the default /docs location. See API Reference. |
| Federated login (OIDC / SSO) | Multi-provider OpenID Connect with PKCE. Pre-built support for Microsoft Entra ID, Google Workspace, Keycloak, and any OIDC-compliant IdP. Managed from the admin UI at runtime. |
| Groups & Resource ACL | Per-connector and per-integration access control lists. Retrieval is filtered at query time — no re-embedding required when ACL changes. Enterprise only. |
| TLS / HTTPS termination | Opt-in HTTPS in the bundled nginx (TLS_ENABLED=1). Supports self-signed, internal CA, and Let's Encrypt certificates. |
| Runtime system settings | Key operational settings (log level, conversation limits, RAG tunables, JWT lifetimes) are managed at runtime via the admin API — no restart required. |
| Sign-out everywhere | Admins can revoke all active sessions globally or per-user. Available on all license tiers. |
| License-gated plan limits | FREE, PRO, and ENTERPRISE tiers with configurable document and storage limits. |
| CPU & GPU support | Works on standard CPU servers and CUDA-capable GPU servers — both inference and embedding. |
Screenshots
Admin: Groups & Access Control
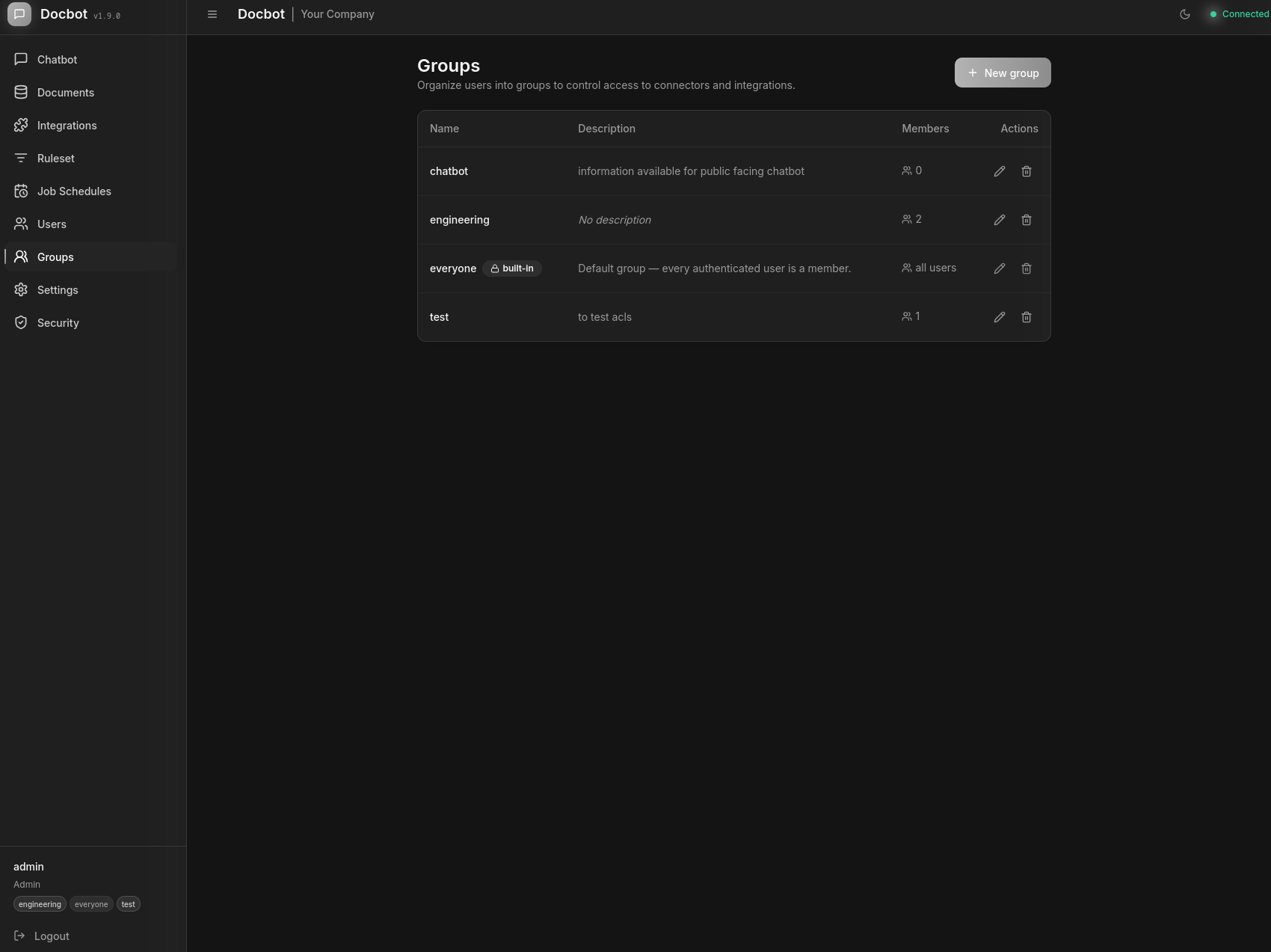
Per-connector and per-integration access control. The built-in everyone group is always present; custom groups (e.g. engineering, chatbot) can be assigned to users and ACLs without re-embedding documents.
Admin: Runtime System Settings
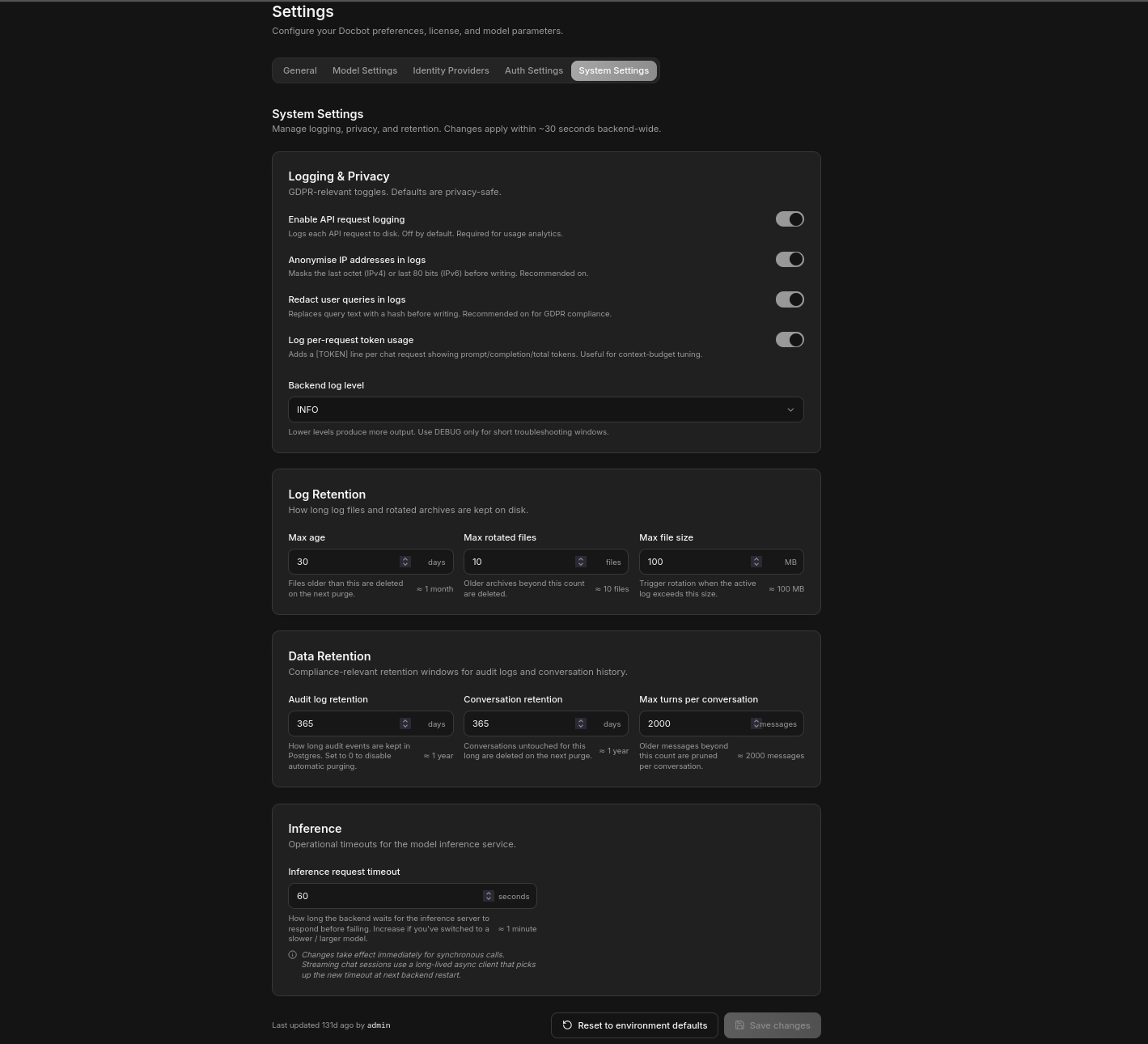
Operational settings — log level, anonymisation, audit/conversation retention, inference timeout — are managed at runtime from the admin UI. No restart required.
Analytics dashboard
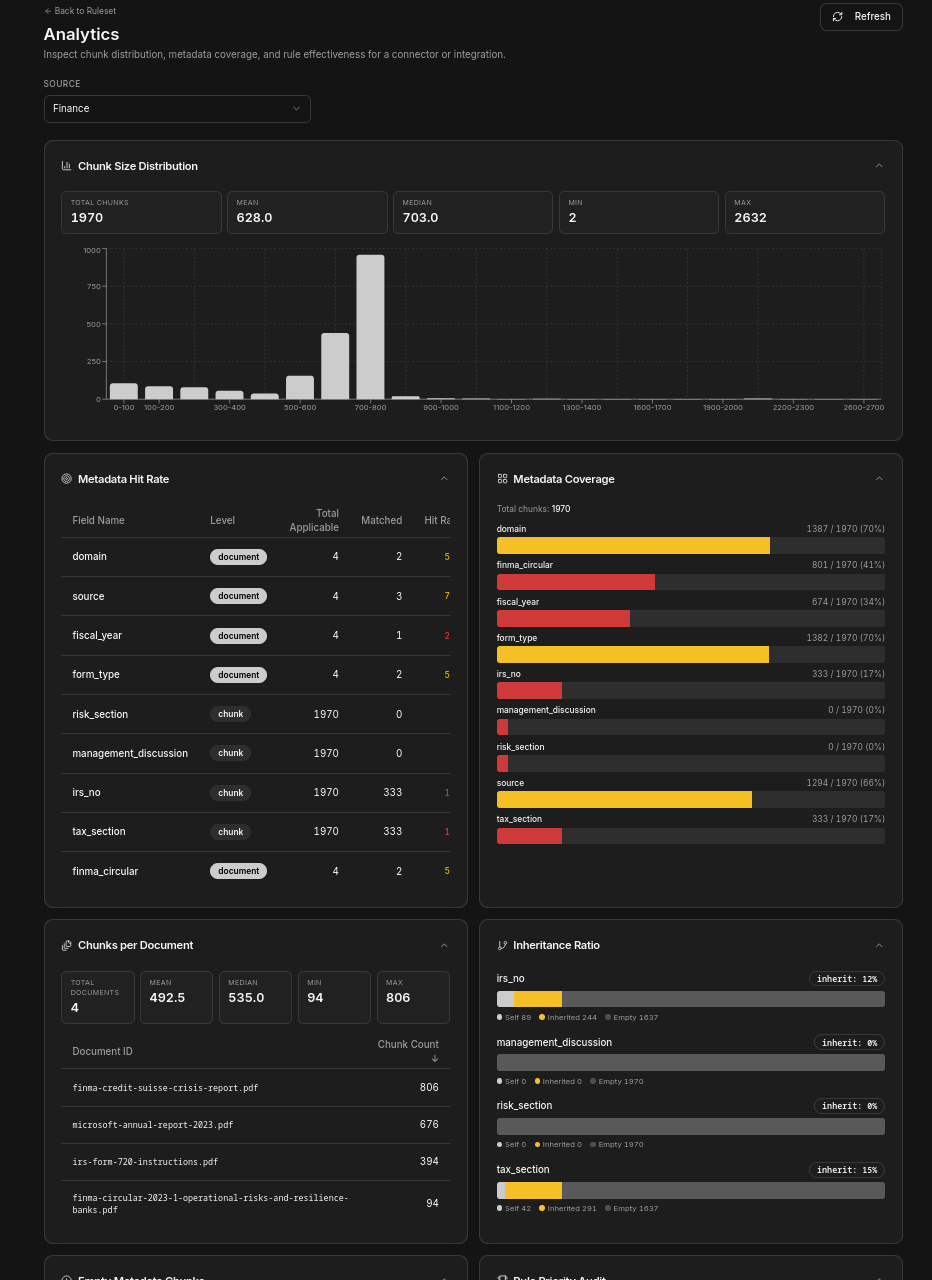
Per-connector and per-integration analytics: chunk-size distribution, metadata hit rate, metadata coverage, chunks per document, and inheritance ratio. Requires the Pro plan.
Current Status
RAG-DocBot is at v1.9.1 and under active development. See the Changelog for the full release history.